Moja pierwsza walka z Dockerem, czyli jak spędziłem 2 godziny szukając błędu, którego nie było
Są technologie, które mijasz latami i myślisz sobie “dobra, kiedyś”. Dla mnie takim byłym zaległym tematem był Docker. Nie dlatego, że nie rozumiałem po co — po prostu w codziennej pracy nigdy nie był potrzebny.
Skąd ten projekt?
W pracy od lat działamy na Azure. VM-ki, App Service, bazy danych jako serwisy zarządzane. Wszystko stabilne, sprawdzone, dobrze skonfigurowane. Docker zawsze był gdzieś na horyzoncie — widać go w tutorialach, w repozytoriach, w ofertach pracy — ale u nas po prostu nie pasował do układanki. Nasze aplikacje działają jako standardowe serwisy i nigdy nie mieliśmy powodu, żeby to zmieniać.
Ale rynek się zmienia. Oczekiwania się zmieniają. I powiem szczerze — nie chciałem być osobą, która patrzy na docker-compose.yml i nie wie od czego zacząć.
Padło więc na projekt poboczny. Mam bloga — tego, który właśnie czytasz — i od jakiegoś czasu zbiera się tam spam w komentarzach. Usuwanie go ręcznie w 2025 roku to czyste marnotrawstwo czasu. Postanowiłem zautomatyzować cały proces i przy okazji postawić sobie coś w pełni skonteneryzowanego.
Stack i plan
Projekt prosty w założeniu: aplikacja webowa do zarządzania komentarzami, baza PostgreSQL, i Ollama z lokalnym modelem językowym do oceniania — spam czy nie spam. Wszystko w Docker Compose, wszystko odizolowane, ładne i schludne.
Zabrałem się do roboty. Skonfigurowałem docker-compose.yml, napisałem trochę kodu do inicjalizacji bazy i połączenia testowego z LLM-em. Podnoszę całość.
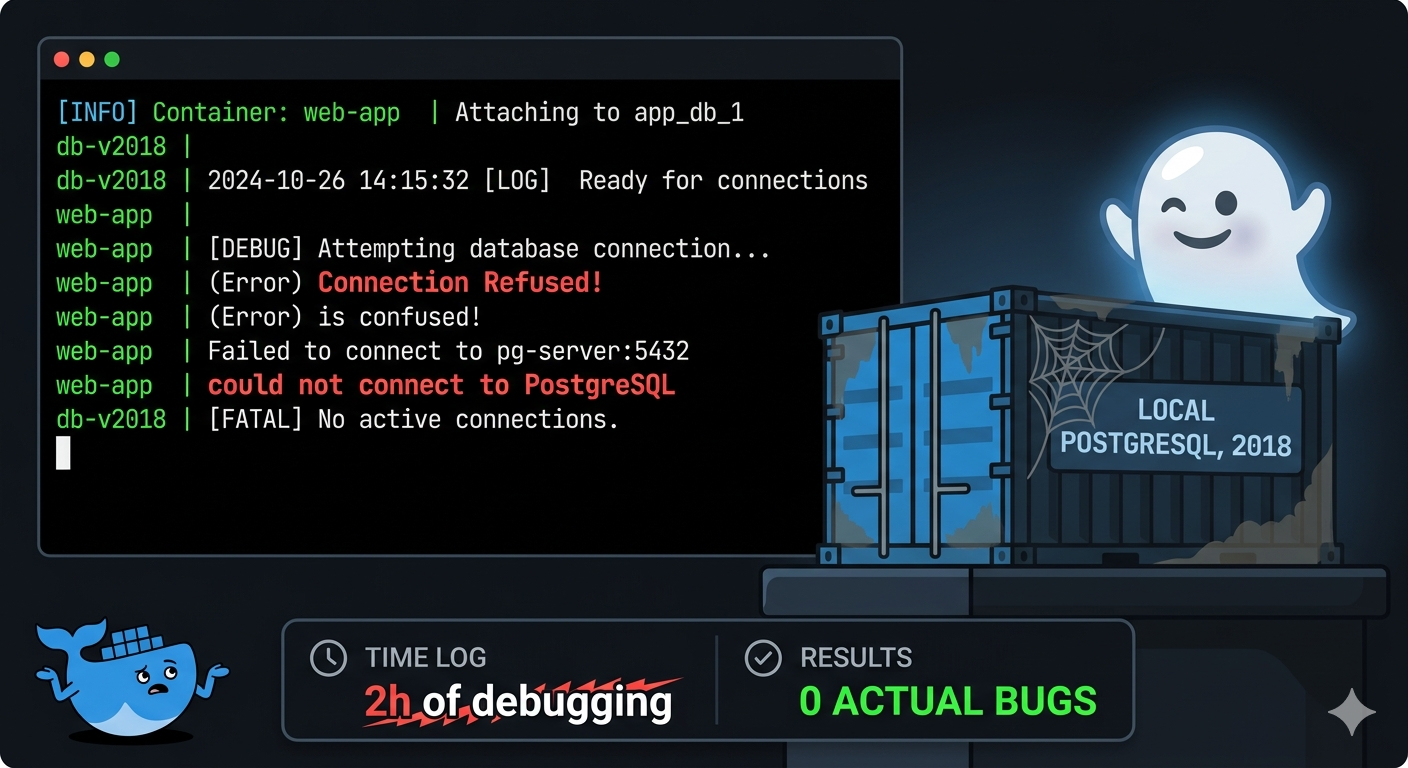
Coś nie działa.
Ollama śmiga. Postgres nie.
Zacząłem od klasyki — odpalenia każdego kontenera osobno. Ollama działa od pierwszego uruchomienia. Serio, bez żadnych niespodzianek. Postgres — tu zaczęły się schody.
Aplikacja wyrzucała błędy połączenia, ale w trochę dziwnym miejscu. Nie tam, gdzie bym się spodziewał przy typowej misconfiguracji. Zacząłem kopać.
Sprawdziłem zmienne środowiskowe. Dobre. Sprawdziłem hasła i nazwy użytkowników. Poprawne. Sprawdziłem, czy kontener w ogóle startuje — startował. Sprawdziłem logi Postgresa wewnątrz kontenera — żadnych błędów. Wszystko wyglądało idealnie, a nic nie działało.
Minęła godzina. Potem półtorej.
Pamięć krótka, port ten sam
Gdzieś przy dwóch godzinach kliknęło.
Jakieś sześć lat temu, w poprzedniej pracy, stawiałem Postgresa lokalnie do testów. Inne dane logowania, inne hasło — ale port? Standardowy. 5432. I ta instancja — zapomniana, cicha, z 2018 roku — wciąż siedziała sobie na moim laptopie.
Aplikacja łączyła się z kontenerem. Poprawnie. Natomiast ja przez dwie godziny próbowałem zrozumieć błędy, które wynikały z konfiguracji tej starej, standalone’owej instancji, z którą nic w projekcie nie miało się łączyć.
Zero bugów w kodzie. Zero problemów z Dockerem. Tylko maszyna z historią i programista z wybiórczą pamięcią.
Czego mnie to nauczyło
Po pierwsze — zanim zaczniesz debugować nowe narzędzie, sprawdź, czy przypadkiem stare środowisko nie kłuje cię w plecy.
Po drugie — Docker jako taki okazał się znacznie mniej straszny, niż myślałem. Ollama stanęła bez żadnej konfiguracji, Compose działa intuicyjnie, izolacja środowisk naprawdę robi robotę.
Po trzecie — takie wpadki to nie powód do wstydu. To są po prostu koszty wchodzenia na nowe terytorium z bagażem wielu lat pracy na innych stackach. Każdy senior developer ma tę listę “głupich błędów” — różnica polega na tym, że senior wie, gdzie ich szukać. A ja właśnie zaktualizowałem swoją listę o port 5432.
Co dalej?
Projekt idzie do przodu. Zostało mi ogarnięcie debugowania Docker Compose z poziomu VS Code — ale po tej przygodzie podchodzę do tego już ze znacznie spokojniejszą głową.
Docker to coś, w co warto było zainwestować czas. Żałuję tylko, że nie zrobiłem tego wcześniej. Ale może właśnie teraz był najlepszy moment — mam konkretny problem do rozwiązania, a to zawsze najlepszy nauczyciel.